How InnoDB writes data on the disk

InnoDB is one of the MySQL storage engine. Likely, it’s the most well-known, the most used, and the most popular one in MySQL storage engines. It’s even the default one when using MySQL.
In this article, I will try to describe what will happen when you execute queries on MySQL with InnoDB.
Why is this article written?
When you are using MySQL as an application developer, you might not need to know the internal architecture of it. Usually there are only a few things which you must know:
- How to connect MySQL from my application?
- How to execute queries to MySQL?
- How can I handle the query result from MySQL?
These are very basic questions which you need to know before writing your application. However, sometimes you might need deeper knowledge about MySQL like below:
- I want to optimize MySQL server. What should I do?
- Which spec database instance should I choose when using public cloud?
- My MySQL instance crashed. How can I fix it?
If you are just an application engineer, you still might not need to answer these questions. However, if your application is big, mission-critical, and needs high reliability, these knowledge must be helpful for you.
In this article, I try to explain how InnoDB handles data (how it saves/lookups data). It’s important to know how InnoDB works internally to make your database usage better. First, I will write how to implement very simple database, which is working but slow. It can be faster by introducing cache, but we also need to keep it ACID compliant to make it work on production environment. InnoDB is an ACID-compliant RDB, but it has a lot of optimization techniques, so I think it’s good to use it as an example to describe how to create ACID compliant RDB which is fast enough.
Before starting this article, let me mention the architecture of MySQL. In MySQL world, the database is made up of 2 layers; the server layer and the storage engine. In MySQL, we can paraphrase the server layer as the frontend of the database. It consists of SQL interface, parser, optimizer and some other components. Storage Engine is actually handles data. In MySQL, storage engine is “pluggable”, and InnoDB is just one of them.
Please note that I will sometimes use the word “database” which means “storage engine”. “Database” is more general, but “storage engine” is a specific word in MySQL.
Too simple database
Let’s put InnoDB aside and start thinking about dead simple database implementation. The simplest database will work like following:
When INSERT, UPDATE, DELETE
- A user executes a query
- The database server opens “data” file for the table
- The database server writes the change to the file
- The database server closes file
- Respond “OK” to the user
When SELECT
- A user executes a query
- The database server opens “data” file for the table
- The database server reads the file and gathers the result which should be returned
- The database server closes file
- Return the result to the user
This implementation has some advantages; it’s quite easy to implement and understand.
The problem of this implementation is its throughput (performance). There are too many disk IO, which is slow. When writing changes, it must update not only actual data, but also index. Because index is b-tree structure, sometimes it has to seek the tree and update several nodes. And usually a table has multiple indices. If a transaction updates multiple tables, it has to access to several tablespace files which requires random access to the disk.
To resolve this problem, you may suggest introducing cache on memory. It will look like this:
When INSERT, UPDATE, DELETE
- A user executes a query
- The database server writes the change on the cache on memory
- Respond “OK” to the user
- Asynchronously, another thread writes the change on the file on the disk in the background
When SELECT
- A user executes a query
- The database server lookups the data on the cache on memory. If not found, reads the data file on the disk and get the result
- Return the result to the user
By introducing cache, the throughput will get increased because lookup on the memory is much faster rather than reading the disk.
At this point, another problem is this implementation is not ACID-compliant.
ACID is a compound word which means Atomicity, Consistency, Isolation and Durability. They are a set of properties of database which guarantee the reliability on its transaction mechanism.
Durability guarantees that when a transaction is committed, the data must remain even if there is a failure (e.g. software crash or power outage).
The caching database which is mentioned above violates the durability. When a transaction is committed, the data is only on the memory and not written to the disk. When a failure occured between writing on the memory and writing on the disk, the committed transaction is lost. This must not happen on ACID-compliant RDB.
A brief summary so far: A simple implementation has disadvantages of the performance, but caching without careful consideration cannot guarantee durability. We found we need durable database which is fast enough.
So, now let’s see how InnoDB achieves both of them.
InnoDB
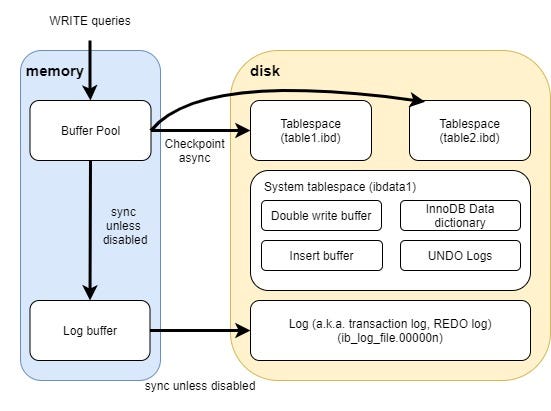
Buffer Pool
As already described, writing on the disk whenever a write operation is executed is slow. InnoDB has a cache. In InnoDB, the cache is called “Buffer Pool”.
Buffer Pool is a list and it works as LRU cache. When reading data, InnoDB tries to fetch the data on the Buffer Pool. If not found, it access the Tablespace file (actual data and index on the disk. It’s named*.ibd) and save the fetched data on the Buffer Pool, then return it.
What will happen when WRITE? InnoDB first writes the data on the Buffer Pool. Also, it writes ”Log”. In next section, let’s see how the Log works and why it’s necessary.
Log
The formal name of the Log is “Redo log”, but it’s usually just called “Log” (filename will look like ib_log_file*). If you have learned how database works, you might know “transaction log”. It’s the same one as “Log” in InnoDB. Some people delete the log file because it’s called “log” because of the lack of understanding, but don’t do that!
The purpose of this log is guaranteeing it never lose the committed transaction in case system failure. It means this log must be on the disk, not on memory.
This log contains updated value. When a system failure occurs, even if there are no backups, just applying the log file from head to bottom will get the data fully back.
In InnoDB, when data is written on the log, it does not write the change on the log file directly. Instead, it first writes on “Log Buffer” on memory, then flush it to the disk. This sounds redundant, but it can be configured not to write on the disk in sync; if you set 0 or 2 (1 by default) as innodb_flush_log_at_trx_commit, it doesn’t write the change on the log file synchronously. However, you who are reading this article will find it’s dangerous and must not be done. If you are interested in the detailed behavior of innodb_flush_log_at_trx_commit, you should refer the MySQL official documentation.
Also, please note that this log is different from “Binlog”. Binlog is written by MySQL server layer, not the storage engine. Some people get confused by them, but they are not the same.
Is it slow because of disk IO, no?
Some of readers might come up with a question; We didn’t want to write the data on the disk whenever a transaction is committed because the disk access requires time? Is it OK to write the log every time?
This question is fair enough, I actually said we don’t want to write the change every time on the disk.
However, writing the change on the tablespece file and writing log is different from performance point of view. There are two differences.
One is that writing log requires only one write system call. Just open the log file and write a line. As already described, applying changes on the tablespace file requires several operations like writing actual data, updating index on possibly several tablespace files.
The other is that writing log is just appending a line at the bottom of the file. It means this is the “sequential access” which does not require the seek time. However, writing actual change on the tablespace file is “random access” which requires random seek on the disk.
Writing on the log file actually requires disk access, but it should be acceptable because of these 2 reasons.
Checkpoint and recovery from failure
Now we know that when a data change is applied, the actual change only exists on the Buffer Pool and not on the tablespace file on the disk. This, the data only on the memory, is called “dirty page”. The reason it’s called “page” is Buffer Pool consists of several “pages”.
Although every transaction log is recorded on the log file, it has to be reflected on the tablespace file because of some reasons:
- When a system failure happens, the data must be restored by the log file. If the tablespace file is much behind the log file (= there are a lot of dirty page), the restore time will be long which makes the restore time long.
- If the server doesn’t have enough memory for the Buffer Pool, InnoDB has to access the tablespace file to get the data. Obviously, when the database’s data volume is bigger then the memory size (to be accurate, bigger than the MySQL config param
innodb_buffer_pool_size), all the data cannot be loaded on the Buffer Pool.
So they’re why “Checkpoint” is needed. When a Checkpoint happens, InnoDB flushes the pages on the Buffer Pool to the tablespace file and write the “Checkpoint record” on the log file. When it recovers from system failure, InnoDB first cheks last checked point and load only the logs after the checkpoint. Because of it, recovery time can get shorter.
There are several Checkpoint algorithms, but InnoDB uses “Fuzzy checkpoint”. “Sharp Checkpoint” is a simple one which is not performant, and the “Fuzzy checkpoint” is light-weight one.
When a checkpoint happens, it can also combine the several changes into one write operation. Let’s say a value is changed from “a” to “b” then “c”, and now “a” is written in the tablespace file. Buffer Pool and transaction log must know all of these changes, but when the chekcpoint happens, mid-value “b” might be ignored because the value is “c” now and no need to write “b”. Even if “b” is written, it must be replaced with “c” immediately. In this case, 2 changes (from “a” to “b”, from “b” to “c”) are combined into one (from “a” to “c”).
This is a technique for optimization which InnoDB actually does, called “Write Combining”. This is actually well not documented on the MySQL official Reference Manual.
Double write buffer
When InnoDB writes dirty pages on the tablespace file, it first writes the change on the “Double write buffer”, then it’s “fsynced” to the tablespace file. This is called “buffer”, but it’s on the disk.
The buffer is used for the restore from a system failure. When a system failure happens, there can be broken or half-written data because of the failure. However, when the restore, these broken data must be fixed. When the double write buffer is enabled, InnoDB guarantees the change is written on the double write buffer, it can restore the broken data from the double write buffer. When the data on the double write buffer is broken, it is restored from log.
If the database server storage or filesystem supports write atomicity, then the double write buffer feature can be disabled for optimization.
Conclusion
In this article I described what will happen internally when WRITE queries are executed on MySQL with InnoDB. With these techniques I described in this article, MySQL is fully ACID-compliant RDB which is fast enough.
Understanding internal architecture will help you better operate the InnoDB, even if you are not a DBA. It is not difficult to come up with very simple database by ourselves, but InnoDB has a lot of optimization techniques and I believe it can be applied into our daily work to build a better software.
Thank you for reading!
References
Book
Jim Gray, Andreas Reuter (1992) Transaction Processing: Concepts and Techniques Morgan Kaufmann
MySQL Official Reference Manual
MySQL Glossary https://dev.mysql.com/doc/refman/5.6/en/glossary.html#glos_buffer_pool
14.5.1. Buffer Pool https://dev.mysql.com/doc/refman/5.6/en/innodb-buffer-pool.html
14.5.4. Log Buffer https://dev.mysql.com/doc/refman/5.6/en/innodb-redo-log-buffer.html
14.6.3.1. The System Tablespace https://dev.mysql.com/doc/refman/5.7/en/innodb-system-tablespace.html
14.12.3 InnoDB Checkpoints
https://dev.mysql.com/doc/refman/5.7/en/innodb-checkpoints.html
15.6.5. Redo Log https://dev.mysql.com/doc/refman/8.0/en/innodb-redo-log.html
Other resources on the Internet
Baron Schwartz’s Website (Seen date: 2021/01/05) “How InnoDB Performs a Checkpoint” https://www.xaprb.com/blog/2011/01/29/how-innodb-performs-a-checkpoint/
Percona Blog (Seen date: 2021/01/05) “XtraDB / InnoDB internals in drawing” https://www.percona.com/blog/2010/04/26/xtradb-innodb-internals-in-drawing/
漢のコンピュータ道 (Seen date: 2021/01/05) “InnoDBのログとテーブルスペースの関係” http://nippondanji.blogspot.com/2009/01/innodb.html
Qiita (Seen date: 2020/12/29) MySQL InnoDBの領域管理 https://qiita.com/SH2/items/654d89759e7e39d999b5
たにしきんぐダム (Seen date: 2021–01–07) “トランザクション技術とリカバリとInnoDBパラメータを調べた” https://tanishiking24.hatenablog.com/entry/innodb-durability
